Lambda表达式,集合,Stream流,不可变集合
发表于|更新于
|阅读量:
Typora+PicGo+阿里云OSS实现云笔记|Typora上传图片https://www.bilibili.com/video/BV1ci4y1L7j8/?spm_id_from=333.337.search-card.all.click&vd_source=3ae7423da4f44e42aa16cee6872b544f
常用快捷键
批量重命名:shift+F6
Lambda表达式(jdk8开始)
lambda表达式概述
1.为了简化匿名内部类的代码的写法
2.语法格式
1
2
3
4
| (匿名内部类被重写方法的形参列表)->{
被重写的方法体代码
}
注意:->是语法形式,无实际含义
|
3.传统实现抽象类或接口的的方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| public class Test {
public static void main(String[] args) {
Animal animal = new Animal() {
@Override
public void run() {
System.out.println("跑起来");
}
};
animal.run();
Food food = new Food() {
@Override
public void eat() {
System.out.println("吃东西");
}
};
food.eat();
}
}
abstract class Animal{
public abstract void run();
}
interface Food{
void eat();
}
|
输出结果
实现demo
1
2
3
4
5
|
Food food1 = ()->{
System.out.println("hahaha");
};
food1.eat();
|
注意:lambda表达式只能实现函数式接口,也就是只有一个抽象方法接口
Lambda表达式的省略规则
1.参数类型可以省略不写,
2.如果只有一个参数,参数类型可以省略不写,同可以()也可以省略
3.如果Lambda表达式的方法体代码只有一行代码,可以省略大括号不写,同时要省略分号!
4.在3的条件下,此时,如果这行代码是return语句,必须省略return不写,同时也必须省略分号
集合
合集的相关问题
1.数组和集合的元素存储的个数问题
- 数组定义后类型确定,长度固定
- 集合类型可以不固定,大小是可变的
2.数据和集合存储元素的类型问题
- 数组可以存储基本类型和引用数据类型的数据
- 集合只能存储引用数据类型的数据
3.数组和集合适合的场景
- 数组适合做数据个数和类型确定的场景
- 集合适合做数据个数不确定,且要做增删元素的场景
集合类体系结构
集合分为Collection(单列)和Map(双列)
Collection:表示的每个元素只包含一个值
Map:每个元素包含两个值(键值对)
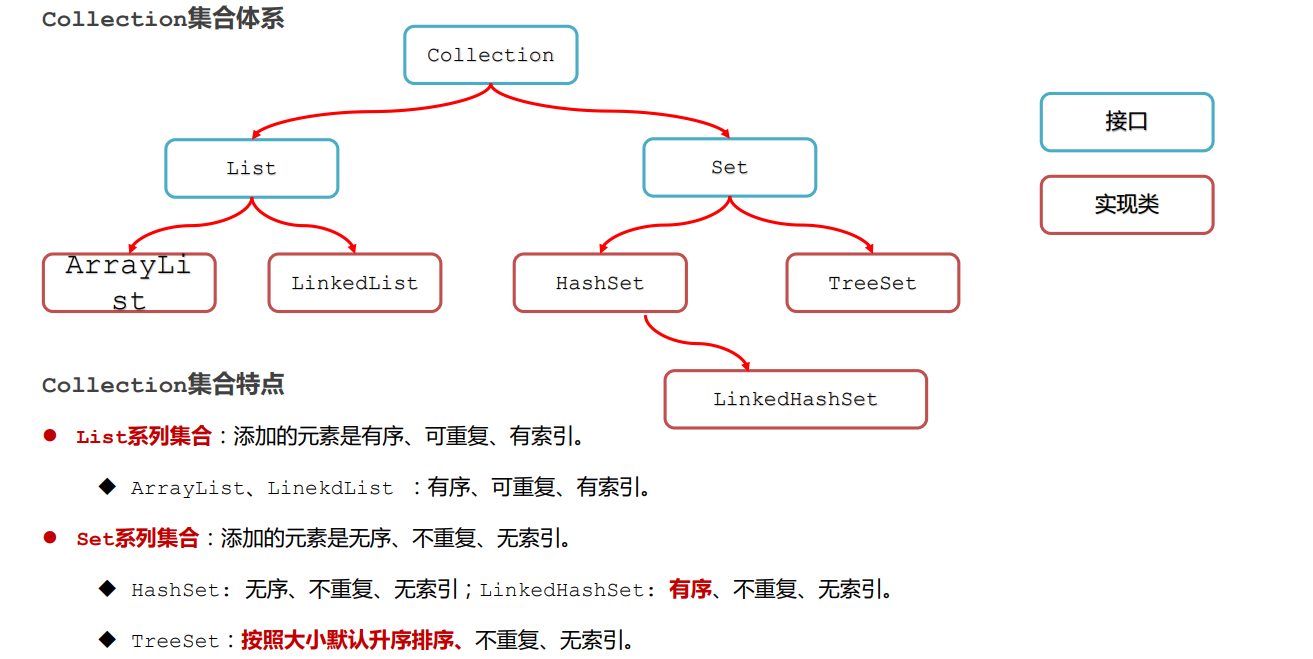
Collection集合体系
泛型
集合都是泛型的形式,可以在编译阶段约束集合只能操作某种数据类型
格式:
1
2
3
| Collection<String> lists = new ArrayList<>();
Collection<String> lists = new ArrayList()
|
注意:集合和泛型都只能支持引用数据类型,不支持基本数据类型,所以集合中存储的元素都以为是对象
如果集合中要存储基本类型的数据怎么办?
1
2
3
|
Collection<Integer> lists = new ArrayList<>();
Collection<Double> lists = new ArrayList<>();
|
Collection集合常用的API
注意:Collection是单列集合的祖宗接口,它的功能是全部单列集合都可以继承使用
| 方法名称 |
说明 |
| public boolean add(E e) |
把给定对象添加到当前集合中 |
| public void clear() |
清空集合中所有的元素 |
| public void remove(E e) |
把给定的对象在当前集合中删除 |
| public boolean contains(Object obj) |
判断当前集合是否包含给定的对象 |
| public boolean isEmpty() |
判断当前集合是否为空 |
| public int size() |
返回集合中元素的个数 |
| public Object[] toArray() |
把集合中元素,存储到数组中 |
迭代器遍历概述
迭代器在java中的代表是Iterator,迭代器是集合的专用的遍历方式
如何获取迭代器?
| 方法名称 |
说明 |
| Iterator iterator() |
返回集合中迭代器对象,该迭代器对象默认指向当前集合的0索引 |
Iterator中的常用方法
| 方法名称 |
说明 |
| boolean hasnext() |
询问当前位置是否有元素存在,存在返回true,不存在返回false |
| E next() |
获取当前的位置的元素,并同时将迭代器对象移向下一个元素。 |
demo
1
2
3
4
5
6
7
8
9
| ArrayList<Object> list= new ArrayList<>();
list.add("good");
list.add("good");
list.add("good");
Iterator<Object> iterator = list.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
|
增强for
语法格式
1
2
3
| for(元素数据类型 变量名 :数组或者Collection){
使用变量名即可
}
|
1
2
3
| for (Object o : list) {
System.out.println(o);
}
|
Lambda表达式遍历集合
| 方法名称 |
说明 |
| default void foreach(Consumer<? super T> action) |
结合lambda遍历集合 |
1
2
3
4
5
6
7
| System.out.println("======");
list.forEach(new Consumer<Object>() {
@Override
public void accept(Object o) {
System.out.println(o);
}
});
|
简化版
1
| list.forEach(o->System.out.println(o));
|
极限简化版
1
2
| list.forEach(System.out::println);
|
List集合特有的方法
| 方法名称 |
说明 |
| void add(int index ,E element) |
在集合的指定位置插入元素 |
| E remve(int index) |
根据索引删除元素,返回被删除的元素 |
| E set (int index , E element) |
修改指定索引处的元素,返回被修改的元素 |
| E get (int index) |
返回指定索引处的元素 |
总结:List 系列集合的特点
ArrayList,LinkedList:有序,可重复,有索引
List的实现类的底层原理
ArrayList底层是基于数组实现的,查询块,增删相对慢
LinkedList底层是基于双链表实现的,查询元素慢,增删首位元素非常快
LinkedList集合特有的方法
| 方法名称 |
说明 |
| public void addFirst(E e) |
在该列表开头插入元素 |
| public void addLast(E e) |
将指定的元素追加到此列表的末尾 |
| public E getFirst() |
获得集合中的第一个元素 |
| public E getLast() |
获得集合中的最后一个元素 |
| public E removeFirst() |
删除一个元素并返回第一个元素 |
| public E removeLast() |
删除最后一个元素并返回最后一个元素 |
集合的并发修改异常
从集合中的一批元素中找到某些元素并啥就拿出,如何操作?
错误demo:使用迭代器进行遍历
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| ArrayList<Object> list= new ArrayList<>();
list.add("1");
list.add("2");
list.add("3");
Iterator<Object> iterator = list.iterator();
while(iterator.hasNext()){
Object next = iterator.next();
if(next=="1"){
list.remove(next);
}
}
|
报错信息:

同样的如果使用foreach删除,或者lambda表达式进行删除也会报错
1
2
3
4
5
6
7
8
| for (Object o : list) {
list.remove(o);
}
list.forEach(o->{
list.remove(o);
});
|
改进方法:不使用集合对象去掉remove,而使用迭代器对象去remove
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| ArrayList<Object> list= new ArrayList<>();
list.add("1");
list.add("2");
list.add("3");
Iterator<Object> iterator = list.iterator();
while(iterator.hasNext()){
Object next = iterator.next();
if(next=="1"){
iterator.remove();
}
}
|
Collections排序相关的API
排序方式1:
| 方法名称 |
说明 |
| public static void sort(List list) |
将集合中元素按照默认的规则排序 |
排序方式2:
| 方法名称 |
说明 |
| public static void sort(List list,Comparator c) |
实现Comperator接口 |
demo
1
2
3
4
5
6
7
8
9
|
Collections.sort(list);
System.out.println(list);
Collections.sort(list, ( o1, o2)-> {
return o2-o1;
}
);
System.out.println(list);
|
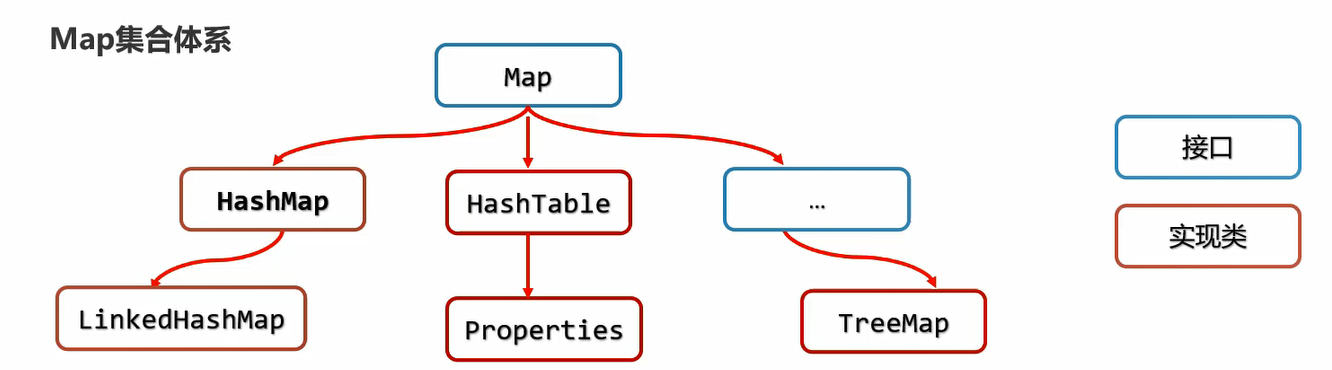
Map集合体系
- 是一种双列集合,每个元素包含两个元素
- 每个元素的格式:key = value(键值对元素)
- 也被称为”键值对集合“
Map集合整体格式
- [key1 = value1,key2 = value2,….]
Map集合体系
说明:
特点:
- Map集合的特点都是由键决定的
- Map集合的键是无序的,不重复的,无索引的,值可以重复
- Map集合后面重复的键对应的值会覆盖前面重复键的值
- Map集合的键值对都可以为null
Map集合实现类的特点
- HashMap:元素按照键是无序,不重复,无索引,值不做要求
- LinkedHashMap:元素按照键是有序,不重复,无索引,值不做要求
- TreeMap:元素按照键是排序,不重复,无索引,值不做要求
demo
1
2
3
4
5
6
7
8
9
|
Map<String, Integer> maps = new LinkedHashMap<>();
maps.put("鸿星尔克", 3);
maps.put("Java", 1);
maps.put("枸杞", 100);
maps.put("Java", 100);
maps.put(null, null);
System.out.println(maps);
|
Map集合常用的API
- Map是双列集合的祖宗接口,它的功能是全部双列集合都可以继承使用
| 方法名称 |
说明 |
| v put(key,v value) |
添加元素 |
| v remove(Object key) |
根据键删除键值对元素 |
| void clear() |
移除所有的键值对元素 |
| boolean containsKey(Object key) |
判断集合是否包含指定的键 |
| boolean containsValue(Object value) |
判断集合是否包含指定的值 |
| boolean isEmpty() |
判断集合是否为空 |
| int size() |
集合的长度,也就是集合中键值对的个数 |
demo
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
Map<String , Integer> maps = new HashMap<>();
maps.put("iphoneX",10);
maps.put("娃娃",20);
maps.put("iphoneX",100);
maps.put("huawei",100);
maps.put("生活用品",10);
maps.put("手表",10);
System.out.println(maps);
System.out.println(maps.isEmpty());
Integer key = maps.get("huawei");
System.out.println(key);
System.out.println(maps.get("生活用品"));
System.out.println(maps.get("生活用品2"));
System.out.println(maps.remove("iphoneX"));
System.out.println(maps);
System.out.println(maps.containsKey("娃娃"));
System.out.println(maps.containsKey("娃娃2"));
System.out.println(maps.containsKey("iphoneX"));
System.out.println(maps.containsValue(100));
System.out.println(maps.containsValue(10));
System.out.println(maps.containsValue(22));
Set<String> keys = maps.keySet();
System.out.println(keys);
System.out.println("------------------------------");
Collection<Integer> values = maps.values();
System.out.println(values);
System.out.println(maps.size());
Map<String , Integer> map1 = new HashMap<>();
map1.put("java1", 1);
map1.put("java2", 100);
Map<String , Integer> map2 = new HashMap<>();
map2.put("java2", 1);
map2.put("java3", 100);
map1.putAll(map2);
System.out.println(map1);
System.out.println(map2);
|
Map集合的遍历方式一:键找值
- 先获取Map集合的全部键的Set集合
- 遍历键的Set集合,然后通过键提取对应的值
键找值涉及到的api
| 方法名称 |
说明 |
| Set keySet() |
获取所有的键的集合 |
| V get(Object key) |
根据键获取值 |
demo
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| public static void main(String[] args) {
Map<String , Integer> maps = new HashMap<>();
maps.put("iphoneX",10);
maps.put("娃娃",20);
maps.put("iphoneX",100);
maps.put("huawei",100);
maps.put("生活用品",10);
maps.put("手表",10);
Set<String> strings = maps.keySet();
for (String string : strings) {
Integer integer = maps.get(string);
System.out.println(string+"="+integer);
}
}
|
Map集合的遍历方式二:键值对
- 先把Map集合转成Set集合,Set集中每个元素都是键值对实体类型了
- 遍历Set集合,然后提取键和值
键值对涉及到的api:
| 方法名称 |
说明 |
| Set<Map.Entry<K,V>> entrySet() |
获取所有键值对对象的集合 |
| K getKey() |
获得键 |
| V getValue() |
获得值 |
demo
1
2
3
4
5
6
| Set<Map.Entry<String, Integer>> entries = maps.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println(key+"==="+value);
}
|
Map集合的遍历方式三:Lambda
| 方法名称 |
说明 |
| default void forEach(BiComsumer<> action) |
遍历Map集合 |
demo
1
2
3
4
5
6
| maps.forEach(new BiConsumer<String, Integer>() {
@Override
public void accept(String s, Integer integer) {
System.out.println(s+"===>"+integer);
}
});
|
Map集合的简单应用
统计100个人的投票情况
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| String[] choose = {"A","B","C","D","E"};
StringBuffer stringBuffer = new StringBuffer();
Random random = new Random();
for (int i = 0; i <100 ; i++) {
stringBuffer.append(choose[random.nextInt(choose.length)]);
}
System.out.println(stringBuffer);
HashMap<Character, Integer> hashMap = new HashMap<>();
for (int i = 0; i <stringBuffer.length() ; i++) {
char c = stringBuffer.charAt(i);
if(hashMap.containsKey(c)){
hashMap.put(c,hashMap.get(c)+1);
}else{
hashMap.put(c,1);
}
}
System.out.println(hashMap);
|
输出结果
1
| {A=18, B=19, C=23, D=18, E=22}
|
HashMap的特点和底层原理
- 由键决定:无序,不重复,无索引。HashMap底层是哈希表结构的。
- 依赖hashCode方法和equals方法保证键的唯一
- 如果键要存储的是自定义对象,需要重写hashCode和equals方法
- 基于哈希表,增删改查的性能都比较好
嵌套集合demo
折叠文本
此处可书写文本 嗯,是可以书写文本的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
| package com.itheima.d9_map_impl;
import java.util.*;
public class MapTest4 {
public static void main(String[] args) {
Map<String, List<String>> data = new HashMap<>();
List<String> selects = new ArrayList<>();
Collections.addAll(selects, "A", "C");
data.put("罗勇", selects);
List<String> selects1 = new ArrayList<>();
Collections.addAll(selects1, "B", "C" , "D");
data.put("胡涛", selects1);
List<String> selects2 = new ArrayList<>();
Collections.addAll(selects2 , "A", "B", "C" , "D");
data.put("刘军", selects2);
System.out.println(data);
Map<String, Integer> infos = new HashMap<>();
Collection<List<String>> values = data.values();
System.out.println(values);
for (List<String> value : values) {
for (String s : value) {
if(infos.containsKey(s)){
infos.put(s, infos.get(s) + 1);
}else {
infos.put(s , 1);
}
}
}
System.out.println(infos);
}
}
|
泛型的深入
泛型的概述和优势
泛型:是jdk5中引入的特性,可以在编译阶段约束操作的数据类型,并并进行检查
泛型的格式:<数据类型>;注意:泛型只能支持引用数据类型
泛型的好处:
统一数据类型。
把运行时期的问题提前到编译期间,避免了强制类型转换可能出现的异常,因为编译阶段类型就能确实下来
泛型可以在很多地方进行定义:
类的后面->泛型类
方法上声明->泛型方法
接口后面->泛型接口
后面再看05、泛型深入、自定义泛型、泛型通配符、上下限.mp4
Set系列集合
特点:
Set集合实现类特点
HashSet:无序,,不重复,无索引
LinkedHashSet:有序,不重复,无索引
TresSet:排序,不重复,无索引
测试不重复的demo
1
2
3
4
5
| HashSet<Object> objects = new HashSet<>();
objects.add("123");
objects.add("123");
objects.add("123");
System.out.println(objects);
|
输出结果:
HashSet底层原理
- HashSet集合底层采取哈希表存储的数据结构
- 哈希表是一种对于增删改查数据性能都比较号的结构
哈希表的构成
JDK8之前,底层使用数组+链表组成
JDK8之后,底层使用数组+链表+红黑树组成
哈希值
- 是JDK根据对象的地址,按照某种规则算出来的int类型的数值
如何获取哈希值?
public int hashCode();返回对象的哈希值
对象的哈希值特点?
- 同一个对象多次调用hashCode()方法返回的哈希值是相同的
- 默认情况下,不同对象的哈希值是不同的
demo
1
2
| String name = "zhangsan";
System.out.println(name.hashCode());
|
输出结果:
HashSet1.7版本原理解析:数组+链表+(结合哈希算法)
- 创建一个默认长度为16的数组,数组名为table
- 根据元素的哈希值跟数组的长度求余计算出应存入的位置
- 判断当前位置是否为null,如果null直接存入
- 如果位置不为null,且不一样,则调用equals方法比较
- 如果一样,则不存,如果不一样,则存入元素
- JDK7新元素占老元素位置,指向老元素
- JDK8新元素挂在老元素下面
HashSet1.8版本原理解析
- 底层结构:数组,链表+红黑树结合体
- 当挂在元素下面的数据过多是,查询性能降低,从JDK8开始之后,当链表长度超过8的时候,自动转换为红黑树
哈希表的详细流程
- 创建一个默认长度为16的数组,数组名为table
- 根据元素的哈希值和数组的长度计算出应存入的位置
- 判断当前位置是否为null,如果为null,直接存入,如果不为null,表示有数据,则调用equals方法比较属性值,如果一样,则不存,如果不一样则入存入数组
- 当数组存满到16*0.75=12时,就自动扩容,每次扩容原先的两倍
如果利用hashSet去除重复的实体类对象
主要是要重写:Object的hashCode和equals
demo
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
| public class Test {
public static void main(String[] args) {
HashSet<Student> set = new HashSet<>();
Student zhangsan = new Student("zhangsan", "11");
Student zhangsan2= new Student("zhangsan", "11");
set.add(zhangsan);
set.add(zhangsan2);
System.out.println(set);
}
}
class Student{
private String name;
private String age;
public Student() {
}
public Student(String name, String age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAge() {
return age;
}
public void setAge(String age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return Objects.equals(name, student.name) && Objects.equals(age, student.age);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age='" + age + '\'' +
'}';
}
}
|
1
| 输出结果:[Student{name='zhangsan', age='11'}]
|
LinkedHashSet集合概述和特点
- 有序,不重复,无索引
- 这里的有序是指保存存储和取出的元素顺序一致
- 原理:底层数据结构是依然哈希表,只是每个元素又额外的多了一个双链表的机制记录存储的顺序
TreeSet集合概述和特点
- 不重复,无索引,可排序
- 可排序:按照元素的大小默认升序(由小到大)排序
- TreeSet集合底层是基于红黑树的数据结构实现排序的,增删改查性能都较好
注意:TreeSet集合是一定要进行排序的,可以将元素按照指定的规制进行排序
默认的排序规则:
- 对于数值类型:升序
- 字符串类型:首字符的编号升序排序
- 自定义类型:无法直接排序
自定义排序规则(treeSet)
方式一
- 让自定义的类实现Comparable接口重写里面的compareTo方法来制定比较规则
核心代码部分:
1
2
| class Student implements Comparable<Student>
|
重写compareTo方法
1
2
3
4
5
| @Override
public int compareTo(Student o) {
return this.age-o.age>=0 ? 1:-1;
}
|
输出结果:
1
2
| [Student{age=2}, Student{age=21}, Student{age=22}, Student{age=25}]
|
方式二
TresSet集合有有参构造器,可以设置Comparator接口对应的比较器对象,来指定比较规则
1
2
3
4
5
6
7
8
9
| TreeSet<Student> students = new TreeSet<>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o1.getAge()-o2.getAge();
return Double.compare(o1.getweight-o2.getweight)
}
});
|
可变参数
- 可变参数用在形参中可以接受多个数据
- 可变参数的参数:数据类型…参数名称
可变参数的作用
- 传输参数非常灵活,方便。可以不传递参数,可以传递1个或者多个,也可以传输一个数组
- 可变参数在方法内部本质上就是一个数组
可变参数的注意事项
- 一个形参列表中可变参数只能有一个
- 可变参数必须放在形参列表后面
Collections集合工具类
- java.utils.Collections:是集合工具类
- 作用:Collections并不属于集合,是用来操作集合的工具类
Collections常用的API
| 方法名称 |
说明 |
| public static boolean addAll |
给集合对象批量添加元素 |
| public static void shuffle(List<?> list) |
打乱List集合元素的顺序 |
demo
1
2
3
4
5
6
7
| ArrayList<Integer> list = new ArrayList<>();
Collections.addAll(list,1,2,3,4,5);
System.out.println(list);
Collections.shuffle(list);
System.out.println(list);
|
创建不可变集合
什么是不可变集合?
- 就是不可以被修改的集合
- 集合的数据项再创建的时候提供,并且在整个生命周期里面,都不可以被修改
为什么要创建不可变集合?
重要数据,且不能修改
如何创建不可变集合?
在List、Set、Map接口中,都存在of方法,可以创建一个不可变的集合
demo
1
| List<Integer> integers = List.of(1, 2, 3, 4, 5);
|
Stream流?
什么是Stream流?
在java8中,得益于Lambda所带来得函数式编程,引入了一个全新得Stream流概念
目的:用于简化集合和数组操作的api
demo
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| ArrayList<String> list = new ArrayList<>();
Collections.addAll(list,"123","12","1234");
ArrayList<Object> list1 = new ArrayList<>();
for (String s : list) {
if(s.startsWith("123")){
list1.add(s);
}
}
list.stream().filter(s -> s.startsWith("123")).forEach(System.out::println);
}
|
各种存储数据的容器添加集合
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
Collection<String> list = new ArrayList<>();
Stream<String> s = list.stream();
Map<String, Integer> maps = new HashMap<>();
Stream<String> keyStream = maps.keySet().stream();
Stream<Integer> valueStream = maps.values().stream();
Stream<Map.Entry<String,Integer>> keyAndValueStream = maps.entrySet().stream();
String[] names = {"赵敏","小昭","灭绝","周芷若"};
Stream<String> nameStream = Arrays.stream(names);
Stream<String> nameStream2 = Stream.of(names);
|
没看完,之后再看:02、Stream流体系.mp4
异常处理
什么是异常?
异常是程序在“编译”或者”执行”的过程中可能出现的问题,注意:语法错误不算在异常体系中。
日志框架
